Better extension performance with Promises
The key to performance is elegance, not battalions of special cases.
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil.
This is an unfinished blog post started some two-and-a-half years ago that is unlikely to ever be finished properly. So I’m publishing it as-is in case anyone finds it useful.
Performance can be very hard to get right. Added performance that comes at the cost of code clarity can be difficult to sustain, and even large investments into performance may be wasted if aimed at a poor target. While choosing where to aim your optimization efforts may never be easy, we’ve recently chosen to focus on one high gain problem area, for both Firefox and its add-ons, and have begun to adopt a coding style which makes gains in this area very nearly free.
While this article will focus mainly on the problem of synchronous IO, the solutions we propose extend to many other areas, from offloading work onto multiple threads, to easing interaction between privileged browser code and asynchronous, sandboxed content processes.
The IO problem
In Firefox, all code which interacts with the UI must run on the main thread. This means that while any JavaScript is running, whether executing complex calculations, or blocking on IO, the UI of the entire browser must remain essentially frozen1. The result is that long-running operations, or relatively short-running operations which happen often, can lead to a laggy and unresponsive browser. This can be such a significant problem that we have a special name for it: jank.
There are many sources of jank, and many ways of addressing them, but here we’re going to focus on what’s proven to be on of the most significant, and easy to fix: IO pauses. These often come from things you might think of as trivial, such as reading a config file from disk. Or from things you think of as expensive, but difficult to handle asynchronously, like SQL queries. Or even things you may think of as madly expensive, but might do anyway, like network IO.
You’d be right to think most of these operations relatively cheap, most of the time. But in aggregate, or in the unusual circumstances which turn out to in fact be very common, they add up to produce a noticeably sluggish UI.
Asynchrony: The complicated solution
The solution to the IO problem is to perform operations
asynchronously. Often this can be fairly simple. Rather than reading
a file by calling a function that returns its contents, you use a
different function which returns them via a callback. Rather than
performing a synchronous XMLHttpRequest2, you use an
asynchronous request with a load event listener. But what happens
when you need to chain multiple IO operations that rely on the
previous operations’ results?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | |
Promises: The complicated made simple
The modern idea of promises arose out of the near ubiquitous need to deal with complex, asynchronous operations. While the concept itself is fairly simple, it goes a long way toward simplifying many problems associated with coordinating multiple sequential operations, wether in parallel, or in sequence, or any particular vaguely-DAG-shaped flow you’d care do imagine.
In promise-based code, any function which operates asynchronously, and might otherwise accept a callback or event listener, returns a promise object instead. A promise object is, as its name suggests, a promise to return a value. Any code with access to this object can register to be notified when the value is available, or the operation is complete.
Each of these promise objects will inevitably end up in one of two states. Either the operation will complete successfully, in which case we say it is resolved, or the operation will fail, in which case we say it is rejected. In either case, the appropriate handlers will be notified.
The above example, in promise-based code, would look something like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
While the differences may appear superficial, the technique offers several advantages over older callback- and event-based approaches. In my opinion, though, the only benefits that really matter are:
-
Consistency: In Promise-based code, all interfaces with return a result asynchronously follow the same pattern. Not only does this simplify API design and usage, and improve readability, but it also allows for the easy creation of utilities which would otherwise be extremely complicated.
For instance, the
Promise.allhelper function consolidates an array of promises into a single promise which resolves once every promise in the array has resolved. This is possible regardless of the API used, or the type of object the promise returns. -
Chaining: Registering a promise handler has the side-effect of creating a new promise to report on the status of the handler itself. When the handler returns, this new promise is resolved with its return value. When it raises an error, the promise is rejected with that error. Most importantly, though, if the handler returns a
Promiseobject, its own promise is resolved or rejected when this new promise is resolved or rejected, with the same value.This behavior allows for the seamless construction of chains of promise handlers which may rely on the values generated by previous handlers, and for functions which return promises to trivially generate results which rely on such chains.
The combination of these two factors leads to a very flexible approach with the power to simplify many types of problem.
Promise basics
Standard promises are created by passing an arbitrary function to
the native Promise constructor3. The function is
executed immediately, with two further functions, resolve and
reject, as arguments. Calling one of these functions will cause
the promise to be resolved, or rejected, as appropriate.
The most basic promise looks something like this:
1 2 3 4 5 6 7 8 | |
Here, we create a very simple promise, which is immediately either
resolved if the variable okay is true, or otherwise
rejected.
To make any use of this result, we need to register a handler:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Or, to put it all together:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Clearly, this example is silly. We could have more concisely written the above as:
1 2 3 4 5 6 | |
The benefits will begin to become clear as our examples become more complex.
Asynchronous resolution: A wrapper for XMLHttpRequest
For a more practical example, let’s look at creating a wrapper for
a basic XMLHttpRequest, as used in the example above:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
This function returns a promise which is resolved or rejected only after the request completes. We’d use it to fetch a simple document as such:
1 2 3 | |
Here, we already see some improvement over the direct
XMLHttpRequest usage. It’s much more concise, for a start. And
while we could achieve similar concision by passing success and
error callbacks, the familiar .then(success, failure) pattern
makes the behavior immediately clear to the reader.
The standardized interface also gives us some reusability benefits.
For instance, if we dispatch a number of requests and need to wait
for all of them to complete before proceeding, we can use the builtin
Promise.all method, without any additional work:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Moreover, we needn’t restrict ourselves to only HTTPRequest
promises, but can use the same Promises.all call to wait for any
number of promises of unrelated types.
Promise handlers in detail
Promise handlers added using the .then() method take two optional
functions as parameters, a success callback and a failure callback,
to be called when the promise is resolved or rejected, respectively.
In their simplest form, these handlers behave no different from
ordinary success and failure callbacks. However, the .then()
function also returns a promise, which is tied to the success or
failure of the handler itself.
If the success callback returns successfully, this promise will
resolve with its return value. Importantly, if the callback returns
a Promise itself, the two promises become linked, and the
handler’s promise is accepted or rejected as if it were the returned
promise.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
Or, without the intermediate variables, as it would idiomatically be written:
1 2 3 4 5 6 7 | |
If exceptions are raised by either the success or failure callbacks,
the handler’s promise will be rejected, with the exception as the
reason. Likewise, the failure callback itself may return a
Promise, which will cause the handler’s promise to be rejected
with its value as the reason.
If the handler is missing either a success or failure callback, then success or failure of the parent promise is propagated directly to the handler’s promise.
Thing!
The beauty of this approach is that it scales very easily to handle complex flows. If, for instance, you need to handle a mix several operations in parallel in series:
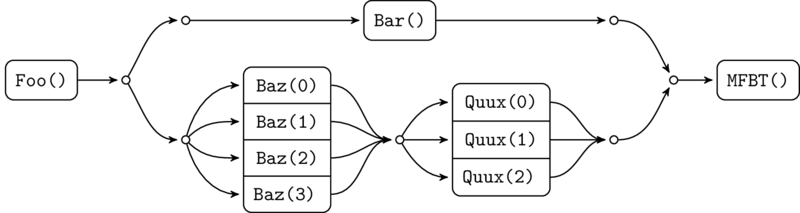
The necessary promise code is simple:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | |
Footnotes
-
This situation will change somewhat with the introduction of Multi-process Firefox, commonly known as electrolysis or e10s. With e10s enabled, while all UI code must still run on the main thread, each content tab runs in its own process, with its own main UI thread. As a result, code blocking the main thread of a content tab will not interfere with the UI of the main browser itself, or of other tabs. ↩
-
This is, in fact, a bit of a misnomer. A synchronous
XMLHttpRequest, rather than actually blocking the main thread, initiates the network request and then continues processing events from the main event loop until it has a response. While this doesn’t cause the same jank issues as hard blocking on IO, it does block interaction with the browser or content window that the request was initiated from, among other problems.Imagine, for instance, that while your
XMLHttpRequestis waiting for its response, another task starts its ownXMLHttpRequest. Your initial request will not return until the second request finishes. While this may seem contrived, there are other “blocking” functions which behave similarly, and this behavior does, in practice, lead to deadlocks. ↩ -
There have been many, often incompatible, implementations of the promise concept in the past. For simplicity, here we focus solely on the more recent ECMAScript Promises standard. ↩